
Анализ пространственных данных может быть чрезвычайно сложной задачей.
Даже если вы хорошо разбираетесь в геоаналитике и data science, путь от поиска и загрузки данных до получения интерактивной карты или отчёта с результатами анализа может оказаться непредсказуемым.
Особенно это касается тех проектов, где приходится иметь дело с большими объёмами данных в несовместимых форматах из многих разрозненных источников. А таких проектов много, если не сказать большинство (плотность населения, данные для вычисления автомобильного и пешеходного потоков с GPS-устройств, данные с сенсоров и датчиков интернета вещей, геоданные социальных сетей, телеметрия и другие часто используемые пространственные данные — это всегда большие наборы данных).
В нашей статье разберём трудности, с которыми приходится сталкиваться в проектах пространственного анализа. Обсудим мировые тренды и то, как они позволяют решать эти проблемы.
И, конечно, рассмотрим и хорошие новости: как современные технологии и no-code платформы делают пространственный анализ доступным, и убедимся в этом на примере.
Как выглядит процесс пространственного анализа
Существует несколько методологий анализа данных, большинство из которых имеют похожие черты. Они представляют собой понятный стандартизированный способ превращения «сырых» данных в готовые решения и прогнозы. Самые известные — это KDD (Knowledge Discovery in Databases), SEMMA (Sample, Explore, Modify, Model, Assess) и CRISP-DM (Cross-Industry Standard Process for Data Mining).
В целом процесс анализа пространственных данных можно разделить на несколько этапов (на примере SEMMA).
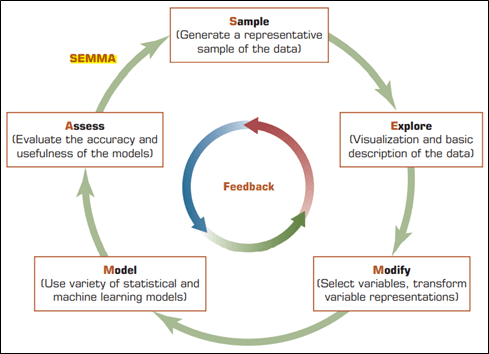
- Сбор и подготовка данных (Sample). На этом этапе собираются пространственные данные из различных источников. Данные очищаются и приводятся к единому формату для дальнейшего анализа.
- Исследование (Explore). Поиск тенденций и аномалий в пространственных данных. Может включать в себя анализ распределения данных по географическим регионам, поиск пространственных корреляций и другие формы исследовательского анализа. Обычно предполагает создание карт и других визуальных представлений данных.
- Модификация данных (Modify). Преобразование и подготовка пространственных данных для анализа. Это может включать создание новых переменных, например, расчёт расстояний или создание пространственных индексов, а также выбор и трансформацию переменных для уточнения модели. Применение различных аналитических методов, таких как анализ расстояний, буферный анализ, построение маршрутов и т. д.
- Моделирование данных (Model). На этом этапе применяются различные аналитические модели для прогнозирования или понимания пространственных явлений. Может включать в себя использование геостатистических методов, пространственного моделирования, машинного обучения и других инструментов для поиска пространственных закономерностей, моделирования сценариев и оценки влияния различных факторов, например, в планировании землепользования или определении оптимального местоположения для магазинов.
- Оценка (Assess). Здесь анализируются полученные результаты, а также оценивается, насколько хорошо модель предсказывает или объясняет интересующие явления. Включает в себя оценку точности, проверку на тестовых данных и интерпретацию результатов в контексте задачи.
На каждом из этих этапов выполняются разные операции обработки пространственных данных. Например, на этапе подготовки данных — геокодирование для превращения адресов в географические координаты, а на этапе анализа — геостатистические методы для изучения связей между данными и SQL-joins для соединения данных из разных наборов данных. Последующие этапы включают в себя такие задачи, как интерпретация полученных результатов, их внедрение в бизнес-процессы и обратная связь для доработки аналитических моделей.
Применяемые методы на каждом этапе могут быть разными — в каждом проекте свои уникальные задачи и подходящие инструменты.
Сложности пространственного анализа
Перечисленные этапы часто трудно реализовать на практике. Основные сложности связаны с необходимостью анализа больших объемов пространственных данных. Эти данные разбросаны по различным источникам и представлены в разнообразных форматах. Для того чтобы их собрать, обработать и подготовить, нужны дорогостоящие вычислительные мощности, а также специалисты, обладающие компетенциями в data science.
Рассмотрим подробнее. Мы выделяем две частые проблемы во время пространственного анализа.
Неудовлетворительная скорость обработки и визуализации пространственных данных в традиционной инфраструктуре
Во многих ГИСах, которые активно работают с большим объёмом данных и проводят сложные вычисления, обработка занимает много времени, иногда даже неприемлемо много. Это проявляется в медленной загрузке данных и создании карт, замедленной «перерисовке» карты при масштабировании и перемещении, а также в длительном времени, необходимом для выполнения различных вычислений.
Необходимость привлечения квалифицированной команды data science для настройки бизнес-процессов
Рост объёма и сложности данных увеличивают нагрузку на команды пространственного анализа и роли всех типов.
От инженеров по обработке данных, задачей которых является создание согласованных и масштабируемых конвейеров, аналитиков, гарантирующих точность и актуальность данных, до специалистов по обработке и разработчиков, сталкивающихся с необходимостью работы с большими объемами данных.
Проекты пространственного анализа требуют специальных навыков и знаний в области геоинформационных технологий, ГИС-инструментов и data science, а также spatial SQL.
Такие знания есть далеко не у всех. Поэтому в следующем разделе рассмотрим тенденции в сфере анализа данных, нацеленные на расширение доступности аналитических инструментов для широкого круга пользователей и снижение зависимости от квалифицированных специалистов.
Мировые тенденции в области аналитики данных
При этом отказ от пространственного анализа, который является чрезвычайно удобным инструментом, из-за существующих сложностей был бы нежелателен.
Тем более, учитывая быстрое развитие технологий и повышенное внимание со стороны Gartner, мировых консалтинговых и технологических компаний, а также сообществ разработчиков открытого и проприетарного программного обеспечения, успешное решение всех проблем становится закономерным.
Переход в облачную инфраструктуру
Системы, которые интенсивно используют большие объёмы данных, нуждаются в большей вычислительной мощности. Для увеличения этой мощности можно использовать параллельные вычисления, что подразумевает одновременную обработку данных с помощью нескольких процессоров или компьютеров. Существует несколько способов это сделать, включая использование многоядерных процессоров, компьютерных кластеров, графических процессоров (GPU — Graphics Process Unit) и облачных вычислений.
Облачные высокопроизводительные вычислительные решения становятся все более доступными, поэтому компании постепенно переводят локальные системы в облако.
Облачная платформа не только решает проблему производительности, но и позволяет оптимизировать расходы на инфраструктуру, благодаря модели «Платишь только за то, что используешь» или Pay-As-You-Go.
Применение пространственных индексов
Идея пространственного индексирования заключается в разбиении поверхности Земли на ячейки, чаще всего квадраты или шестиугольники. Каждая ячейка затем «наполняется» данными о объектах в её периметре. К примеру, это может быть численность населения, количество жилых зданий, точки интереса, заказы интернет-магазина за определённый период, автобусные остановки и многое другое.
Системы индексирования поддерживают иерархию ячеек, т. е. каждая «родительская» ячейка может быть поделена на вложенные «дочерние» ячейки, а также отношения между соседними ячейками.
Широко применять пространственные индексы начали Uber (система пространственных индексов H3) и Google (S2). Со временем технологии пространственной индексации интегрируются в основные распространённые хранилища данных.
Применение пространственных индексов заметно ускоряет процессы анализа больших наборов данных, вычисления расстояний, площади и т. д., поиска соседних областей, позволяет выполнять динамическую агрегацию данных в ячейках, а также ускоряет объединение пространственных данных из разных источников и обеспечивают их согласованность.
Использование этих технологий не только ускоряет пространственный анализ данных, но и обеспечивает интеграцию данных, особенно при работе со сторонними данными. Если внешний поставщик данных предоставляет пространственные данные, уже отформатированные в одной из этих систем пространственной индексации, это заметно упрощает процесс их объединения с существующими данными пользователя.
Аналитика самообслуживания (Self-service Analytics)
Аналитика самообслуживания — это форма бизнес-аналитики, при которой специалистам предоставляется возможность выполнять запросы и генерировать отчёты самостоятельно при минимальной ИТ-поддержке.
Встроенная аналитика
Цифровое рабочее место обогащается возможностью встроенной аналитики, когда анализ данных осуществляется непосредственно в рамках обычного бизнес-процесса пользователя, избавляя от необходимости переключаться на другое приложение. Этот подход часто используется в специфических процессах, например, при оптимизации маркетинговой кампании, конверсии потенциальных клиентов, планировании спроса на товарно-материальные запасы и в других случаях.
Это даёт возможность пользователям, особенно тем, у кого нет специализированных навыков работы с данными, получать информацию о своих бизнес-операциях. Такой подход не только упрощает процесс анализа данных, но и даёт возможность принимать решения на основе данных в режиме реального времени.
Как эти тенденции влияют на распределение ролей в компаниях
Такие тенденции размывают границы между аналитиками данных и отраслевыми экспертами. Раньше аналитика данных, data science и бизнес-анализ считались отдельными дисциплинами с уникальными методами и инструментами, выполняемыми различными подразделениями. Однако в последнее время появляются решения, способствующие их интеграции.
Слияние этих областей оказывает влияние не только на технологии, но и на людей, а также на процессы внутри организаций.
К примеру, специалист по развитию розничной сети теперь может анализировать данные о покупках, выручке, трафике и плотности населения для создания моделей машинного обучения.
Эти модели предсказывают выручку и помогают оптимизировать запасы товаров в новых магазинах, включая этапы сбора данных из разных источников, их очистку и последующий анализ работы сети магазинов с применением алгоритмов машинного обучения для прогнозирования продаж.
Весь процесс может быть выполнен экспертом самостоятельно, без привлечения команды data science и разработчиков.
Далее посмотрим, какие решения для этого есть.
Автоматизация процесса пространственного анализа и no-code workflow платформы
Рассмотренные выше тенденции отражают растущую потребность в инструментах, которые делают пространственную аналитику доступной для пользователей с любым уровнем подготовки, и интегрированной в текущие бизнес-процессы компании.
Мы разработали такой инструмент — это Epsilon Workflow.
Представьте себе конструктор для построения процессов из пространственных операций и моделей машинного обучения.
Выбор наборов данных и задач, которые необходимо выполнить с их помощью, осуществляется путём выбора соответствующих кубиков и их последующего соединения в единые процессы.
На каждом шаге видите промежуточный результат на карте или в таблице, и можете уточнить или скорректировать этот шаг, если нужно.
Каждый доступный кубик соответствует определённой операции над пространственными данными, spatial SQL-запросу или модели машинного обучения.
Состав этих функций широкий, всё не перечислишь: от импорта и геокодирования данных до расчёта времени в пути, построения буферов и изохрон. Вы можете работать с матрицами расстояний, искать ближайших соседей, определять вхождение точек в полигоны, проводить геостатистический анализ и настраивать фильтры. Доступны пространственные соединения, агрегирование данных, возможности комбинирования внешние наборы данных со своими, операции по созданию линий, полигонов и точек, методы пространственной кластеризации и использование пространственных индексов, создание полигонов Делоне, измерение площади и многие другие функции и сервисы. Также есть возможность выбрать и встроить в процесс предопределённые модели предиктивной аналитики.
Всё делается без написания кода или SQL-запросов.
Операции выполняются в вашем облачном хранилище данных. Если оно пока отсутствует, доступ предоставляется в специально выделенном хранилище в облаке Epsilon On Point. Поэтому все запросы обрабатываются быстро.
Как только результаты workflow будут готовы, вы можете визуализировать их на карте, затем сохранить её и при необходимости опубликовать, установив правила разграничения прав доступа. Вы также можете отправить данные на электронную почту в удобное время и в подходящем формате, сохранить их в файле GeoParquet для использования в Geopandas или создать новые таблицы в вашем хранилище данных. Все эти действия выполняются в рабочем окружении Epsilon On Point.
После создания workflow его можно сохранить для использования в операционных процессах: предоставить доступ коллегам, настроить регулярный или однократный автоматический запуск на определённое время, а также повторно применять в различных бизнес-процессах и при разработке приложений.
К тому же так как мы используем SQL-запросы, весь workflow превращается в SQL-код. Это значит, что вы можете не только посмотреть на этот код, но и, если захотите, менять его сами.
Разработка no-code и low-code инструментов для настройки и внедрения процесса цифровых изменений
Мне очень нравится Epsilon Workflow, потому что он делает пространственный анализ доступным для всех. Этот инструмент могут использовать как профессионалы в области анализа данных, так и те, кто в программировании и SQL совсем не разбирается.
Дополнительное преимущество Epsilon Workflow заключается в использовании современных технологий: это облачные хранилища, сервисы для обработки данных, Spatial SQL и машинное обучение. Эти технологии позволяют работать с большими объёмами пространственных данных из разных источников и нашего Каталога данных.
Посмотрите видео, где я представляю наш инструмент no-code геоанализа, который позволяет автоматизировать сложные пространственные процессы без использования SQL и программирования.
Нам интересно, как вы будете использовать Epsilon Workflow. Выберите удобное время, чтобы мы провели для вас демонстрацию, и давайте попробуем вместе.


